CRDS Rules (Mappings)
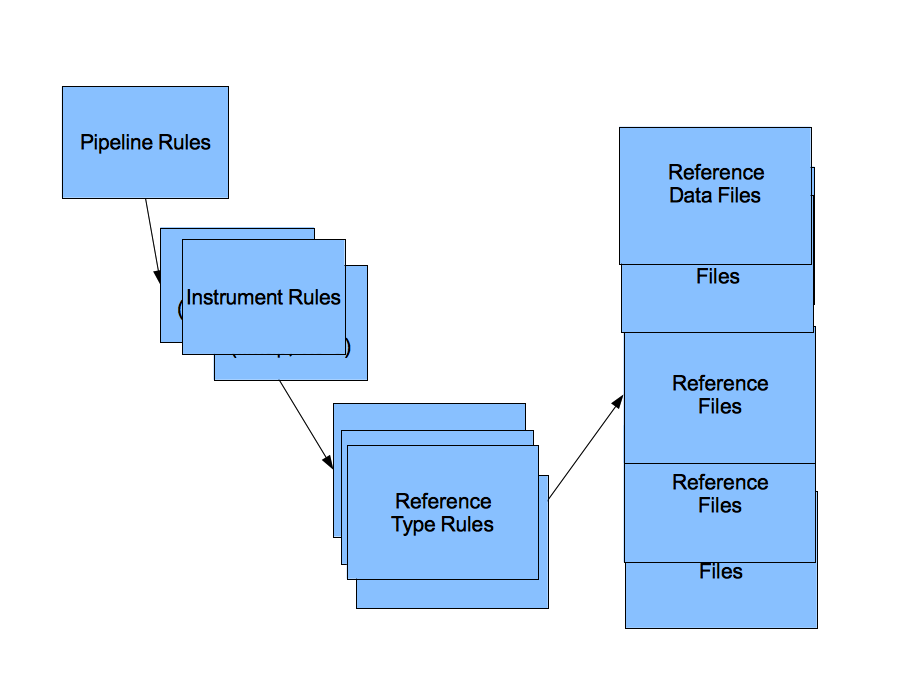
CRDS mappings are organized in a 3 tier hierarchy: pipeline (.pmap), instrument (.imap), and reference (.rmap). Based on dataset parameters, the pipeline context is used to select an instrument mapping, the instrument mapping is used to select a reference mapping, and finally the reference mapping is used to select a reference file.
CRDS mappings are written in a subset of Python and given the proper global definitions can be parsed directly by the Python interpreter. Nothing precludes writing a parser for CRDS mappings in some other language.
Naming
The CRDS HST mapping prototypes which are generated from information scraped from the CDBS web site are named with the forms:
<observatory> .pmap e.g. hst.pmap
<observatory> _ <instrument> .imap e.g. hst_acs.imap
<observatory> _ <instrument> _ <filekind> .rmap e.g. hst_acs_darkfile.rmap
The names of subsequent derived mappings include a version number:
<observatory> _ <version> .pmap e.g. hst_00001.pmap
<observatory> _ <instrument> _ <version> .imap e.g. hst_acs_00047.imap
<observatory> _ <instrument> _ <filekind> _ <version> .rmap e.g. hst_acs_darkfile_00012.rmap
Basic Structure
All mappings have the same basic structure consisting of a “header” section followed by a “selector” section.
header
The header provides meta data describing the mapping. A critical field in the mapping header is the “parkey” field which names the dataset parameters (nominally FITS keywords, JWST or Roman data model names) which are used by the selector to do a best references lookup.
comment
An optional multi-line comment block can be added between the header and selector sections.
selector
The selector provides matching rules used to look up the results of the mapping. The selector is a nested tree structure consisting of top-level selectors and sub-selectors.
Pipeline Mappings (.pmap)
A sample pipeline mapping looks like:
header = { 'name' : 'hst.pmap', 'derived_from' : 'created by hand 12-23-2011', 'mapping' : 'PIPELINE', 'observatory' : 'HST', 'parkey' : ('INSTRUME',), 'description' : 'Initially generated on 12-23-2011', 'sha1sum' : 'e2c6392fd2731df1e8d933bd990f3fd313a813db', } comment = """This is an optional mapping section used to add multiline commentary, perhaps to describe mapping evolution or unusual behaviors. """ selector = { 'ACS' : 'hst_acs.imap', 'COS' : 'hst_cos.imap', 'NICMOS' : 'hst_nicmos.imap', 'STIS' : 'hst_stis.imap', 'WFC3' : 'hst_wfc3.imap', 'WFPC2' : 'hst_wfpc2.imap', }
A pipeline mapping matches the dataset INSTRUME header keyword against its selector to look up an instrument mapping file.
header = { 'derived_from' : 'jwst_0865.pmap', 'description' : 'Hand-edit to define all step parameter reftypes for all instruments', 'mapping' : 'PIPELINE', 'name' : 'jwst_0866.pmap', 'observatory' : 'JWST', 'parkey' : ('META.INSTRUMENT.NAME',), 'sha1sum' : '4d92bebc8cc9819019c7f603c58985bf53b37d9f', } selector = { 'FGS' : 'jwst_fgs_0101.imap', 'MIRI' : 'jwst_miri_0279.imap', 'NIRCAM' : 'jwst_nircam_0198.imap', 'NIRISS' : 'jwst_niriss_0175.imap', 'NIRSPEC' : 'jwst_nirspec_0252.imap', 'SYSTEM' : 'jwst_system_0026.imap', }
A pipeline mapping matches the dataset META.INSTRUMENT.NAME header keyword against its selector to look up an instrument mapping file.
header = { 'derived_from' : 'roman_0036.pmap', 'description' : 'Updated parkey to include roman prefix.', 'mapping' : 'PIPELINE', 'name' : 'roman_0037.pmap', 'observatory' : 'ROMAN', 'parkey' : ('ROMAN.META.INSTRUMENT.NAME',), 'sha1sum' : '7765a10e18b1607ba268c62033f38130bb995690', } selector = { 'WFI' : 'roman_wfi_0035.imap', }
A pipeline mapping matches the dataset ROMAN.META.INSTRUMENT.NAME header keyword against its selector to look up an instrument mapping file.
Restricting the ASDF Standard version
The pipeline mapping supports an optional asdf_standard_requirement header field
that restricts the ASDF Standard version of all .asdf files and .fits files that contain
an embedded ASDF file. The value should be a pip-style version specification,
e.g., ==1.4.0, 0, >=1.4.0, <1.4.5. When a file containing ASDF data is
certified against a context that includes an asdf_standard_requirement, it will
fail unless the ASDF Standard version obeys the requirement.
Instrument Mappings (.imap)
Instrument mappings match the desired reference file type against the reference mapping used to determine a best reference recommendation for a particular dataset. An instrument mapping lists all possible reference types for all modes of the instrument, some of which may not be appropriate for a particular mode.
A sample instrument mapping for HST’s COS instrument looks like:
header = { 'derived_from' : 'hst_cos_0290.imap', 'instrument' : 'COS', 'mapping' : 'INSTRUMENT', 'name' : 'hst_cos_0291.imap', 'observatory' : 'HST', 'parkey' : ('REFTYPE',), 'sha1sum' : '85184c1656b487e7af686a7ab75262dcefc882e8', } selector = { 'badttab' : 'hst_cos_badttab_0250.rmap', 'bpixtab' : 'hst_cos_bpixtab_0254.rmap', 'brftab' : 'hst_cos_brftab_0250.rmap', 'brsttab' : 'hst_cos_brsttab_0250.rmap', 'deadtab' : 'hst_cos_deadtab_0250.rmap', 'dgeofile' : 'hst_cos_dgeofile_0002.rmap', 'disptab' : 'hst_cos_disptab_0259.rmap', 'flatfile' : 'hst_cos_flatfile_0254.rmap', 'fluxtab' : 'hst_cos_fluxtab_0261.rmap', 'geofile' : 'hst_cos_geofile_0250.rmap', 'gsagtab' : 'hst_cos_gsagtab_0253.rmap', 'hvtab' : 'hst_cos_hvtab_0259.rmap', 'lamptab' : 'hst_cos_lamptab_0251.rmap', 'phatab' : 'hst_cos_phatab_0250.rmap', 'proftab' : 'hst_cos_proftab_0265.rmap', 'spottab' : 'hst_cos_spottab_0004.rmap', 'spwcstab' : 'hst_cos_spwcstab_0251.rmap', 'tdstab' : 'hst_cos_tdstab_0254.rmap', 'tracetab' : 'hst_cos_tracetab_0265.rmap', 'twozxtab' : 'hst_cos_twozxtab_0266.rmap', 'wcptab' : 'hst_cos_wcptab_0255.rmap', 'xtractab' : 'hst_cos_xtractab_0257.rmap', 'xwlkfile' : 'hst_cos_xwlkfile_0002.rmap', 'ywlkfile' : 'hst_cos_ywlkfile_0002.rmap', }
For HST, the header keywords FILETYPE or CDBSFILE are used to define a reference's type and corresponding rmap.
FILETYPE is in turn translated to the keyword names used to record reference files in datasets (CRDS names these “filekind”),
and these appear directly in rmap names, e.g. FILETYPE=BIAS translates to BIASFILE which appears in the rmap hst_acs_biasfile_0250.rmap. NOTE: the HST .imap's incorrectly specify REFTYPE in the .imap's but the value is unused.
A sample instrument mapping for JWST’s MIRI instrument looks like:
header = { 'derived_from' : 'cloning tool 0.03b (2012-09-11)', 'instrument' : 'MIRI', 'mapping' : 'INSTRUMENT', 'name' : 'jwst_miri_0000.imap', 'observatory' : 'JWST', 'parkey' : ('REFTYPE',), 'sha1sum' : '08e984a020ad8b617904b6bf18c6a1864f365270', } selector = { 'AMPLIFIER' : 'jwst_miri_amplifier_0000.rmap', 'DARK' : 'jwst_miri_dark_0000.rmap', 'FLAT' : 'jwst_miri_flat_0000.rmap', 'LINEARITY' : 'jwst_miri_linearity_0000.rmap', 'MASK' : 'jwst_miri_mask_0000.rmap', 'PHOTOM' : 'jwst_miri_photom_0000.rmap', }
For JWST, the header keyword REFTYPE (META.REFTYPE) is used to select the rmap. The REFTYPE appears directly in file names, e.g. REFTYPE=SUPERBIAS is part of the rmap name jwst_nirspec_superbias_0001.rmap.
A sample instrument mapping for Roman’s WFI instrument looks like:
header = { 'derived_from' : 'roman_wfi_0034.imap', 'instrument' : 'WFI', 'mapping' : 'INSTRUMENT', 'name' : 'roman_wfi_0035.imap', 'observatory' : 'ROMAN', 'parkey' : ('REFTYPE',), 'sha1sum' : 'd5a58741d5f8a4c2b9cedb89a34a1495dc00ada8', } selector = { 'AREA' : 'roman_wfi_area_0002.rmap', 'DARK' : 'roman_wfi_dark_0014.rmap', 'DISTORTION' : 'roman_wfi_distortion_0003.rmap', 'FLAT' : 'roman_wfi_flat_0015.rmap', 'GAIN' : 'roman_wfi_gain_0006.rmap', 'LINEARITY' : 'roman_wfi_linearity_0006.rmap', 'MASK' : 'roman_wfi_mask_0006.rmap', 'PHOTOM' : 'roman_wfi_photom_0004.rmap', 'READNOISE' : 'roman_wfi_readnoise_0012.rmap', 'SATURATION' : 'roman_wfi_saturation_0006.rmap', }
For Roman, the header keyword REFTYPE (ROMAN.META.REFTYPE) is used to select the rmap. The REFTYPE appears directly in file names, e.g. REFTYPE=DARK is part of the rmap name roman_wfi_dark_0001.rmap.
Reference Mappings (.rmap)
A sample reference mapping for HST COS DEADTAB looks like:
header = { 'derived_from' : 'generated from CDBS database 2014-05-09 23:24:57.840119', 'filekind' : 'DEADTAB', 'instrument' : 'COS', 'mapping' : 'REFERENCE', 'name' : 'hst_cos_deadtab_0250.rmap', 'observatory' : 'HST', 'parkey' : (('DETECTOR',), ('DATE-OBS', 'TIME-OBS')), 'reffile_format' : 'TABLE', 'reffile_required' : 'NONE', 'reffile_switch' : 'DEADCORR', 'rmap_relevance' : '(DEADCORR != "OMIT")', 'sha1sum' : 'bde314f1848b67891d6309b30eaa5c95611f86e2', } selector = Match({ ('FUV',) : UseAfter({ '1996-10-01 00:00:00' : 's7g1700gl_dead.fits', }), ('NUV',) : UseAfter({ '1996-10-01 00:00:00' : 's7g1700ql_dead.fits', }), })
Reference mapping selectors are constructed as a nested hierarchy of selection operators which match against various dataset header keywords.
A sample reference mapping for JWST MIRI DARK looks like
header = { 'derived_from' : 'cloning tool 0.03b (2012-09-11)', 'filekind' : 'DARK', 'instrument' : 'MIRI', 'mapping' : 'REFERENCE', 'name' : 'jwst_miri_dark_0000.rmap', 'observatory' : 'JWST', 'parkey' : (('META.INSTRUMENT.DETECTOR', 'META.INSTRUMENT.FILTER', 'META.EXPOSURE.READPATT'),), 'sha1sum' : '2535d3be806c6e7f5f0da1f2dce64034f9028ddc', } selector = Match({ ('MIRIFULONG', 'ANY', 'FAST') : 'jwst_miri_dark_0000.fits', ('MIRIFULONG', 'ANY', 'SLOW') : 'jwst_miri_dark_0001.fits', ('MIRIFUSHORT', 'ANY', 'FAST') : 'jwst_miri_dark_0002.fits', ('MIRIFUSHORT', 'ANY', 'SLOW') : 'jwst_miri_dark_0003.fits', ('MIRIMAGE', 'ANY', 'FAST') : 'jwst_miri_dark_0004.fits', ('MIRIMAGE', 'ANY', 'SLOW') : 'jwst_miri_dark_0005.fits', })
Reference mapping selectors are constructed as a nested hierarchy of selection operators which match against various dataset header keywords.
A sample reference mapping for Roman WFI FLAT looks like:
header = { 'classes' : ('Match', 'UseAfter'), 'derived_from' : 'roman_wfi_flat_0002.rmap', 'file_ext' : '.asdf', 'filekind' : 'FLAT', 'filetype' : 'FLAT', 'instrument' : 'WFI', 'ld_tpn' : 'wfi_flat_ld.tpn', 'mapping' : 'REFERENCE', 'name' : 'roman_wfi_flat_0002.rmap', 'observatory' : 'ROMAN', 'parkey' : (('META.INSTRUMENT.DETECTOR', 'META.INSTRUMENT.OPTICAL_ELEMENT'), ('META.OBSERVATION.DATE', 'META.OBSERVATION.TIME')), 'sha1sum' : 'bf0119bfbe1d8e5010eb3bec87bc45d575ae8313', 'suffix' : 'flat', 'text_descr' : 'Flat Field', 'tpn' : 'wfi_flat.tpn', } selector = Match({ ('WFI01', 'F158') : UseAfter({ '2020-01-01 00:00:00' : 'roman_wfi_flat_0001.asdf', }), })
Reference mapping selectors are constructed as a nested hierarchy of selection operators which match against various dataset header keywords.
Reference mapping selectors are constructed as a nested hierarchy of selection operators which match against various dataset header keywords.
Active Header Fields
Many rmap header fields are passive metadata. A number of optional rmap header fields, however, actively affect best reference lookups and results:
header = { ..., 'parkey' : (('DETECTOR',), ('DATE-OBS', 'TIME-OBS')), 'extra_keys' : ('XCORNER', 'YCORNER', 'CCDCHIP'), 'reffile_switch' : 'BIASCORR', 'reffile_required' : 'YES', 'rmap_relevance' : '((DETECTOR != "SBC") and (BIASCORR != "OMIT"))', 'rmap_omit' : '((DETECTOR != "SBC") and (BIASCORR != "OMIT"))', 'parkey_relevance' : { 'binaxis1' : '(DETECTOR == "UVIS")', 'binaxis2' : '(DETECTOR == "UVIS")', 'ccdgain' : '(DETECTOR == "IR")', 'samp_seq' : '(DETECTOR == "IR")', 'subtype' : '(DETECTOR == "IR")', }, 'hooks' : { 'fallback_header' : 'fallback_header_acs_biasfile_v2', 'precondition_header' : 'precondition_header_acs_biasfile_v2', }, ..., }
Required Parameters
Required matching parameters for computing best references are defined by the union of 3 header fields: parkey,
extra_keys, and reffile_switch. There is no requirement to use all 3 forms, the latter two forms were added
to model and emulate aspects of HST’s CDBS system, the precursor to CRDS.
parkey
The primary location for defining best references matching parameters is the parkey field.
The simplest form of parkey is a tuple of parameter names used in a lookup by a non-nested selector, as is
seen in pipeline and instrument mappings above.
In reference mappings, the header parkey field is a tuple of tuples. Each stage of the nested selector
consumes the next tuple of header keys. The same parameter set and matching structure is shared by all sections
of a single rmap. For mode-specific parameters, two approaches are availble: use a separate .rmap for each
parameter combination, or fill in unused parameters for a particular mode with the value ‘N/A’.
For the HST COS DEADTAB example above, the Match operator matches against the value of the dataset keyword ‘DETECTOR’. Based on that match, the selected UseAfter operator matches against the dataset’s ‘DATE-OBS’ and ‘TIME-OBS’ keywords to lookup the name of a reference file.
There is no default for parkey.
extra_keys
extra_keys specifies a tuple of parameter names which will not be used in the matches directly, but may be used by
rmap header expressions and hook functions to influence matching. Listing parameters in extra_keys ensures that the
CRDS infrastructure will request the parameters from the server or dataset files and make them available during best
references computations and logical expression evaluation. All parameters used in logical expressions must be
explicitly defined and listed. Undefined parameters are evaluated with the value ‘UNDEFINED’.
If omitted, extra_keys defaults to (), no extra keys.
reffile_switch
Nominally names a dataset keyword generally of the form <type>CORR with keyword values ‘PERFORM’ and ‘OMIT’.
If reffile_switch is not ‘NONE’, it specifies an extra keyword value is to fetch from the dataset.
If reffile_switch is omitted or ‘NONE’, no keyword value is fetched from the dataset.
The runtime checking reffile_switch is used for must be explicitly implemented as part of an rmap_relevance or
rmap_omit expression as seen in the example header; reffile_switch only specifies an extra parameter to fetch
for use in logical expressions and matching. It is logically equivalent to adding the parameter to extra_keys.
Logical Header Expressions
A number of the subsequently described features employ logical expressions which are evaluated at match-time based on the values in the dataset header. There are several things to point out:
Logical expressions are evaluated in the context of the required parameters discussed above.
Dataset matching parameters appear in logical expressions in upper case, without quotes, like global variables.
The entire expression is enclosed in parentheses to tell CRDS to leave case as-is.
Logical expressions are limited to a restricted subset of Python expressions, not arbitrary Python. In particular arbitrary Python function calls are not permitted.
reffile_required
Defines what should happen if an rmap lookup cannot find a match for a particular reference type.
reffile_required has legal values ‘YES’, ‘NO’, and ‘NONE’.
If reffile_required is ‘YES’, failing to find a match results in an exception and/or ERROR.
If reffile_required is ‘NONE’, CDBS did not define reffile_required for this type, so it is assumed to be required.
If reffile_required is ‘NO’, failing to find a match results in assigning the value ‘N/A’ rather than failing.
rmap_relevance
rmap_relevance is a logical expression which is evaluated in the context of dataset header variables.
If rmap_relevance evaluates to True, then a full match is performed and the resulting bestref is returned.
If rmap_relevance evaluates to False, then the match is short circuited and ‘N/A’ is assigned.
parkey_relevance
parkey_relevance defines a mapping from dataset matching parameters to logical expressions.
parkey_relevance is evaluated in the context of the entire set of matching parameters and mutates the specified parameter to ‘N/A’ if the expression evaluates to False, i.e. the parameter is not relevant in the context of the other parameter values.
When a parameter value of ‘N/A’ is used for matching, the parameter is effectively ignored.
hooks
The hooks header section defines functions which are used for special case processing for complex reference assignments. The existing hooks were devised to emulate similar special case handling performed by CRDS’s predecessor system CDBS.
The original <100 series of HST rules had implicit hooks. CRDS rules >200 have hooks which are explicitly named in the ‘hooks’ section of the header which indicates that customized matching is being performed. Running crds.bestrefs with –verbosity=60 wil issue log messages describing hook operations.
new hook functions can only be added with a new release of CRDS code. hook functions have versioned names and should never be modified after use in operations since that would change the meaning of historical .rmaps. Instead, a new hook function should be added and the .rmap header modified to assign it.
hook functions can be ‘unplugged’ in the latest .rmap by setting the value of the hook to ‘none’. Removing the ‘hooks’ section of the .rmap header, or removing individual hook names, currently results in reversion to <100 series .rmap behavior and the original implicit hook functions.
precondition_header
The precondition_header hook is used to mutate incoming dataset matching parameters. precondition_header is sometimes justified as reductive, written in terms of extra_parkeys which do not appear in the matching tuples, and used to mutate a broad range of matching parameter values onto a narrower set of parameter values known to be handled in the .rmap. In essence, when a precondition_header hook is used, the dataset matching parameters become a function of themselves.
fallback_header
The fallback_header hook is used to mutate incoming dataset matching parameters similar to precondition_header. The fallback_header hook is called when the first matching attempt for dataset parameters fails. fallback_header computes a set of matching parameters used for a second matching attempt which will return normally if succesful.
Selectors
All the CRDS selection operators are written to select either a return value or a nested operator. In the case of HST, the Match operator locates a nested UseAfter operator which in turn locates the reference file.
Primitive Return Values
Ultimately the result of every selector lookup is some form of return value to which various CRDS operations can be applied: best references assignment, file distribution, file certification, file differencing, etc.
Single Filename
The most typical return value is a single reference filename. In the case of GEIS files, for the data+header file pair the header is specified in rmaps but both components are distributed.
Filename Tuple
A tuple of primitive filenames can be specified. All files in the tuple are synchronized and returned as best references. The nominal application of a file tuple is for the bracket selector where the files are used for pipeline side interpolations between the two references to generate a synthetic reference.
Not Applicable
A value of N/A can be assigned in place of a filename. This applies the full
power of the matching system to the specification of instrument modes for which
a reference type does not apply. For JWST and Roman, this feature is used to perform data
driven WCS processing based on CRDS reference file assignments. Ultimately the
best reference assigned is N/A, nominally explicitly recorded for the type
keyword. No file is distributed or prefetched. N/A may be specified in place
of a reference file or an rmap file. In the case of specifying N/A for an rmap
file (in the imap/instrument mapping), that type becomes N/A for all modes of
that instrument.
Omit
Similar to N/A, a value of OMIT can be specified in place of a filename. OMIT
can be used to completely remove a type from the best references response. No
file is synchronized or processed, and no best reference should be recorded in
the dataset header for that type. This feature is currently unused.
Match
Based on a dataset`s header values, Match locates the match tuple which best matches the dataset. Conceptually this is a dictionary lookup. In actuality, CRDS processes each match parameter in succession, at each step eliminating match candidates that cannot possibly match.
Parameter Tuples and Simple Matches
The CRDS Match operator typically matches a dataset header against a tuple which defines multiple parameter values whose
names are specified in the rmap header parkey:
("UVIS", "F122LP") : 'some_file_or_nested_selection'
Alternately, for simple use cases the Match operator can match against single strings, which is a simplified syntax for a 1-tuple:
'UVIS' : 'some_file_or_nested_selection'
('UVIS',) : 'this_is_the_equivalent_one_tuple'
Single Parameter Values
Each value within the match tuples of a Match operator can be an expression in its own right. There are a number of special values associated with each match expression: Ors |, Wildcards *, Regular Expressions (), Literals {}, Relationals, between, N/A, and Substitutions.
Or |
Many CRDS match expressions consist of a series of match patterns separated by vertical bars. The vertical bar is read as “or” and means that a match occurs if either pattern matches that dataset header. For example, the expression:
("either_this|that","1|2|3") : "some_file.fits"
will match:
("either_this", "2")
and also:
("that", "1")
Wild Cards *
By default, * is interpreted in CRDS as a glob pattern, much like UNIX shell file name matching. * matches any sequence of characters. The expression:
("F*122",) : "some_file.fits"
will match any value starting with “F” and ending with “122”.
Regular Expressions
CRDS can match on true regular expressions. A true regular expression match is triggered by bracketing the match in parentheses ():
("(^F[^13]22$)",) : "some_file.fits"
The above corresponds to matching the regular expression “^F[^1234]22$” (note that the bracketing parentheses within the string are removed.) Regular expression syntax is explained in the Python documentation for the re module. The above expression will match values starting with “F”, followed by any character which is not “1” or “3” followed by “22”.
Literal Expressions
A literal expression is bracketed with curly braces {} and is matched without any interpretation whatsoever. Hence, special characters like * or | are interpreted literally rather than as ors or wildcards. The expression:
("{F|*G}",) : "some_file.fits"
matches the value “F|*G” as opposed to “F” or anything ending with “G”.
Relational Expressions
Relational expressions are bracketed by the pound character #. Relational expressions do numerical comparisons on the header value to determine a match. Relational expressions have implicit variables and support the operators:
> >= < <= == and or
The expression:
("# >1 and <37 #",) : "some_file.fits"
will match any number greater than 1 and less than 37.
Between
A special relational operator “between” is used to simply express a range of numbers >= to the lower bound and < the upper bound, similar to Python slicing:
("between 1 47",) : "some_file.fits"
will match any number greater than or equal to 1 and less than 47. This is equivalent to:
("# >=1 and <47 #",) : "some_file.fits"
Note that “between” matches sensibly stack into a complete range. The expressions:
("between 1 47",) : "some_file.fits"
("between 47 90", ) : "another_file.fits"
provide complete coverage for the range between 1 and 90.
N/A
Some rmaps have match tuple values of “N/A”, or Not Applicable. A value of N/A is matched as a special version of “*”, matching anything, but not affecting the “weight” of the match:
('HRC', 'N/A') : "some_file.fits"
There are a couple uses for N/A parameters. First, sometimes a parameter is irrelevant in the context of the other parameters. So for an rmap which covers multiple instrument modes, a parameter may not apply to all modes. Second, sometimes a parameter is relevant to custom lookup code, but is not used by the match directly. In this second case, the “N/A” parameter may be used by custom header preconditioning code to assist in mutating the other parameter values that are used in the match.
NOT Expressions
It’s possible to match the negation of match expressions by pre-pending “NOT ” to the unnegated expression. For example:
('not HRC', 'N/A') : "not_some_file.fits"
The weight of a negated expression is the opposite of unnegated weight of the expression: -1 -> 1, 1 -> -1, 0 -> 0.
Substitution Parameters
Substitution parameters are short hand notation which eliminate the need to duplicate rmap rules. In order to support WFC3 biasfile conventions, CRDS rmaps permit the definition of meta-match-values which correspond to a set of actual dataset header values. For instance, when an rmap header contains a “substitutions” field like this:
'substitutions' : {
'CCDAMP' : {
'G280_AMPS' : ('ABCD', 'A', 'B', 'C', 'D', 'AC', 'AD', 'BC', 'BD'),
},
},
then a match tuple line like the following could be written:
('UVIS', 'G280_AMPS', '1.5', '1.0', '1.0', 'G280-REF', 'T') : UseAfter({
Here the value of G280_AMPS works like this: first, reference files listed under that match tuple define CCDAMP=G280_AMPS. Second, datasets which should use those references define CCDAMP to a particular amplifier configuration, e.g. ABCD. Hence, the reference file specifies a set of applicable amplifier configurations, while the dataset specifies a particular configuration. CRDS automatically expands substitutions into equivalent sets of match rules.
Match Weighting
Because of the presence of special values like regular expressions, CRDS uses a winnowing match algorithm which works on a parameter-by-parameter basis by discarding match tuples which cannot possibly match. After examining all parameters, CRDS is left with a list of candidate matches.
For each literal, *, or regular expression parameter that matched, CRDS increases its sense of the goodness of the match by 1. For each N/A that was ignored, CRDS doesn’t change the weight of the match. The highest ranked match is the one CRDS chooses as best. When more than one match tuple has the same highest rank, we call this an “ambiguous” match. Ambiguous matches will either be merged, or treated as errors/exceptions that cause the match to fail. Talk about ambiguity.
For the initial HST rmaps, there are a number of match cases which overlap, creating the potential for ambiguous matches by actual datasets. For HST, all of the match cases refer to nested UseAfter selectors. A working approach for handling ambiguities here is to merge the two or more equal weighted UseAfter lists into a single combined UseAfter which is then searched.
The ultimate goal of CRDS is to produce clear non-overlapping rules. However, since the initial rmaps are generated from historical mission data in CDBS, there are eccentricities which need to be accomodated by merging or eventually addressed by human beings who will simplify the rules by hand.
UseAfter
The UseAfter selector matches an ordered sequence of date time values to corresponding reference filenames. UseAfter finds the greatest date-time which is less than or equal to ( <= ) EXPSTART of a dataset. Unlike reference file and dataset timestamp values, all CRDS rmaps represent times in the single format shown in the rmap example below:
selector = Match({
('HRC',) : UseAfter({
'1991-01-01 00:00:00' : 'j4d1435hj_a2d.fits',
'1992-01-01 00:00:00' : 'kcb1734ij_a2d.fits',
}),
('WFC',) : UseAfter({
'1991-01-01 00:00:00' : 'kcb1734hj_a2d.fits',
'2008-01-01 00:00:00' : 't3n1116mj_a2d.fits',
}),
})
In the above mapping, when the detector is HRC, if the dataset’s date/time is before 1991-01-01, there is no match. If the date/time is between 1991-01-01 and 1992-01-01, the reference file ‘j4d1435hj_a2d.fits’ is matched. If the dataset date/time is 1992-01-01 or after, the recommended reference file is ‘kcb1734ij_a2d.fits’
SelectVersion
The SelectVersion() rmap operator uses a software version and various relations
to make a selection:
selector = SelectVersion({
'<3.1': 'cref_flatfield_65.fits',
'<5': 'cref_flatfield_73.fits',
'default': 'cref_flatfield_123.fits',
})
While similar to relational expressions in Match(), SelectVersion() is
dedicated, simpler, and more self-documenting. With the exception of default,
versions are examined in sorted order.
ClosestTime
The ClosestTime() rmap operator does a lookup on a series of times and selects
the closest time which either precedes or follows the given parameter value:
selector = ClosestTime({
'2017-04-24 00:00:00': "cref_flatfield_123.fits",
'2018-02-01 00:00:00' : "cref_flatfield_222.fits",
'2019-04-15 00:00:00': "cref_flatfield_123.fits",
})
So a parameter of ‘2017-04-25 00:00:00’ would select ‘cref_flatfield_123.fits’.
GeometricallyNearest
The GeometricallyNearest() selector applies a distance relation between a
numerical parameter and the match values. The match value which is closest to
the supplied parameter is chosen:
selector = GeometricallyNearest({
1.2 : "cref_flatfield_120.fits",
1.5 : "cref_flatfield_124.fits",
5.0 : "cref_flatfield_137.fits",
})
In this case, a value of 1.3 would match ‘cref_flatfield_120.fits’.
Bracket
The Bracket() selector is unusual because it returns the pair of selections which
enclose the supplied parameter value:
selector = Bracket({
1.2: "cref_flatfield_120.fits",
1.5: "cref_flatfield_124.fits",
5.0: "cref_flatfield_137.fits",
})
Here, a parameter value of 1.3 returns the value:
('cref_flatfield_120.fits', 'cref_flatfield_124.fits')